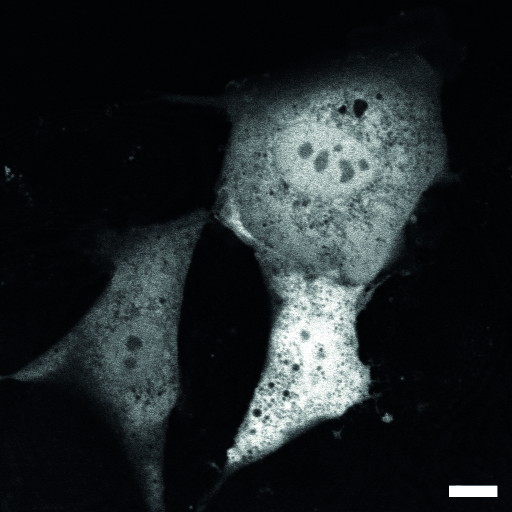
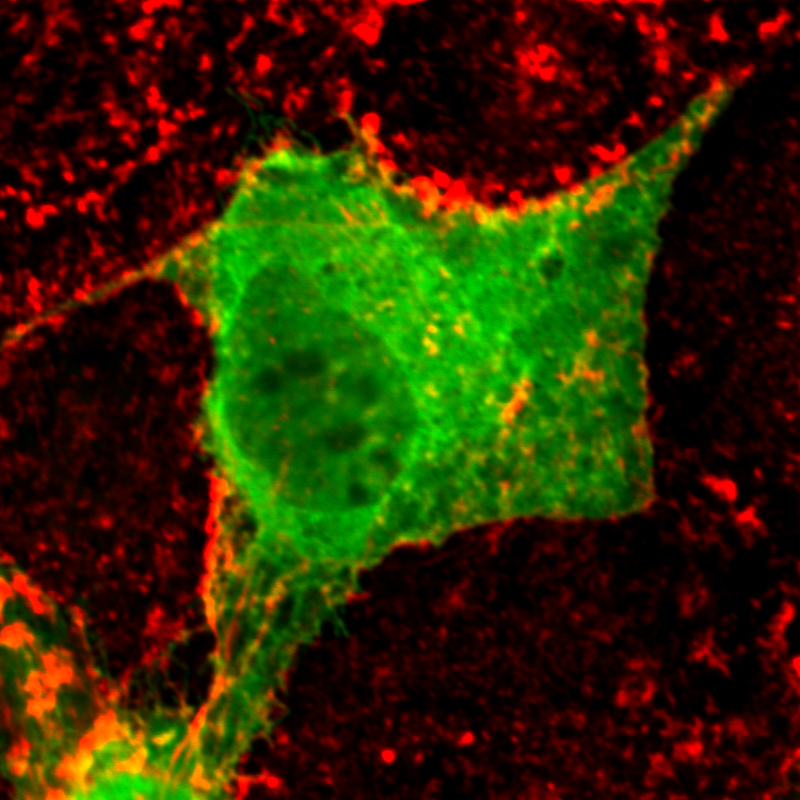
| organism |
orgs |
| Organism: |
Homo sapiens |
Nucleotide Sequence
>ARHGAP40
atggatcagcttccccagaagaatctcctgcgactacaccctgctggctctgctggctgt
tccactggagtggagagctccagcatggatggcttttggatggaggtggaacagatccaa
cagagagatgagctgagggaagaggacagtggcgggaatgaaggccagcttccagaggaa
ggggaagctgaatcccagtggctgcaggacacaggcctgtcgggcctccttggtggcctg
ggcttggatggtgatcaccaggagctcctgtccaccctgacacagacccaggtggccgct
gtgtgccgccggctggacatctatgctcgctcagtgcgaagacaacacaagacacctgtc
agagatgtcagggatgtctttggggtcttcaattcagggaaaatgtcgtcagagaatggc
gactccggtatgaagggggcccagctcagttccggggcctctaagtttcctccagcagca
gagcctggggggctgcaggagcaggctgggagggaagaagccttcaacatggactctgcc
tactcagaacaagctgcggtgctcctgcagaggagcaggccatcccggggaggcacctct
gcctggggcaagtgttccctgccgaagtttaccgtccccaaaggcagacttggcgtgacg
aggataggagacttgtccctgcaggatatgaggaaggtaccttctctggccctcatagag
ctgaccgcgctctgtgacatcctcggcttggacctgaagaggagcaaggcggggaagtgg
aaagcggcagaaactcgcctctttggtgtgccccttgacagcctgctagaagctgaccac
aaagtcctccccagcacacaggtcccgctggtccttcaagccctgctgtcctgtttggaa
aagagaggactggacatggaaggcattctcagggtgcccggatcccaggccagggtcaag
gggctggaacagaaactggagagagacttctatgctggcctttttagctgggacgaggtt
catcacaatgacgcctctgatttgctcaaaaggttcatccggaagctgccgacacctttg
ctcacggctgagtacctcccggccttcgccgtggtgcctaacatccccaacctgaagcag
cgcctgcaggttcttcacctgctcatcctcatcctcccagaacccaacagaaatgcctta
aaggcactgctggaattcctcaggaaggtggtggcccgggaacagcacaacaagatgact
ctgaggaatgtttccaccgtgatggcccctaacctctttctgcaccaagggcggcccccc
aagctccccaaaggcaaggagaagcagctggcagaaggggcagccgaggtggtgcagata
atggtgcactaccaggatctgctgtggacggtcgcctctttcctggtcgcccaggtgcga
aaactgaacgacagtagcagcaggcgcccccagctctgcgacgcaggcctcaagacttgg
ctgcggaggatgcacgcagacagggacaaggcgggggacggcctcgaggcgactcccaag
gtggcaaagatccaggtggtctggcctatcaaggaccccttgaaggtgcctctcaccccc
agcaccaaagtggcccacgtcctgaggcagttcacagagcacctcagccctggttccaag
ggtcaagaagacagtgaggacatggacagcctccttctacaccataggtccatggagtca
gccaacatcctcctctatgaagttggagggaatatcaatgagcatcgcctggacccagat
gcctacctcttagatctgtaccgtgccaacccgcatggtccttttggcttttgggaggcg
gagactgagactggagtccagaggaccaaggaggacgaggtaactgccgtggtccaggtg
ggagaaaatgtcgagacccgggtaattgcggctgagctgtccgaggtgctgacggctggg
cgagaggagcggttgaatgtatgcacaacgcccagagggactgctattggcaaagtgatg
gccccacagggaccaaatgtgaagctaaagcaggatacgcaggtcggagataaggccaag
aacagattccctttagcgctcaagtgctgtttgtcagaaattgacagccccacggccctg
gccggaatgtactgcatgaataaagacccctctgtggtgggacccagctgcccgaaggtc
agcccctgtgaattaatta
Protein Sequence
>ARHGAP40
MDQLPQKNLLRLHPAGSAGCSTGVESSSMDGFWMEVEQIQQRDELREEDSGGNEGQLPEE
GEAESQWLQDTGLSGLLGGLGLDGDHQELLSTLTQTQVAAVCRRLDIYARSVRRQHKTPV
RDVRDVFGVFNSGKMSSENGDSGMKGAQLSSGASKFPPAAEPGGLQEQAGREEAFNMDSA
YSEQAAVLLQRSRPSRGGTSAWGKCSLPKFTVPKGRLGVTRIGDLSLQDMRKVPSLALIE
LTALCDILGLDLKRSKAGKWKAAETRLFGVPLDSLLEADHKVLPSTQVPLVLQALLSCLE
KRGLDMEGILRVPGSQARVKGLEQKLERDFYAGLFSWDEVHHNDASDLLKRFIRKLPTPL
LTAEYLPAFAVVPNIPNLKQRLQVLHLLILILPEPNRNALKALLEFLRKVVAREQHNKMT
LRNVSTVMAPNLFLHQGRPPKLPKGKEKQLAEGAAEVVQIMVHYQDLLWTVASFLVAQVR
KLNDSSSRRPQLCDAGLKTWLRRMHADRDKAGDGLEATPKVAKIQVVWPIKDPLKVPLTP
STKVAHVLRQFTEHLSPGSKGQEDSEDMDSLLLHHRSMESANILLYEVGGNINEHRLDPD
AYLLDLYRANPHGPFGFWEAETETGVQRTKEDEVTAVVQVGENVETRVIAAELSEVLTAG
REERLNVCTTPRGTAIGKVMAPQGPNVKLKQDTQVGDKAKNRFPLALKCCLSEIDSPTAL
AGMYCMNKDPSVVGPSCPKVSPCELI