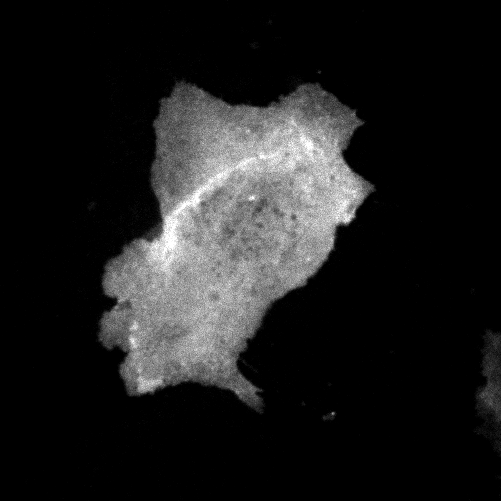
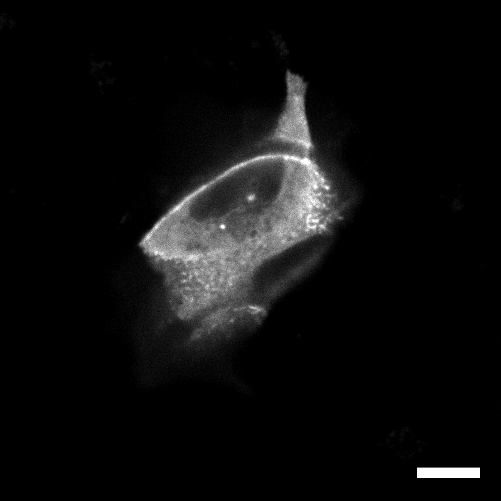
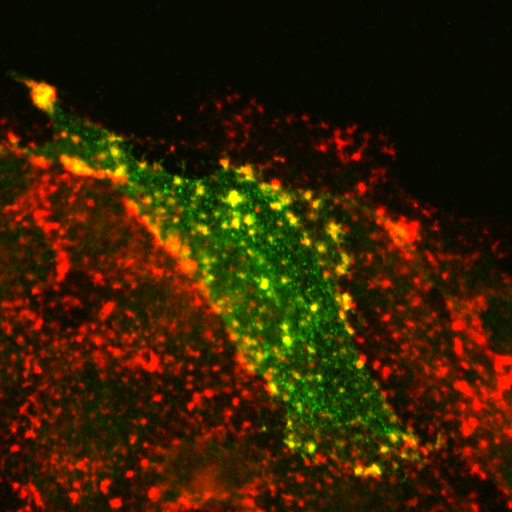
| organism |
orgs |
| Organism: |
Homo sapiens |
Nucleotide Sequence
>ARHGEF18
atgacggtctctcagaaagggggtccccagccaacaccgagcccggctggccctgggacg
caactcggaccaatcacaggagagatggatgaagccgattctgcgtttttaaaatttaag
cagacagctgatgactctctgtcccttacatctccaaacaccgagtccatttttgtagaa
gatccctacaccgcctcgctgaggagtgagattgagtcagacggccacgagtttgaagct
gagtcctggagcctcgccgtggatgcagcctacgccaagaagcaaaagagggaggtggtg
aaaagacaagatgtcctttatgagctgatgcagacagaggtgcaccacgtgcggacgctc
aagatcatgctgaaggtgtactccagggccctgcaggaggagctgcagttcagcagcaag
gccattggccgcctcttcccatgcgctgacgacctgctggagacgcacagccacttcctc
gctcggctcaaggagcgccgccaggagtccctggaggagggcagtgaccggaattatgtc
atccagaaaatcggcgacctcctggttcagcagttttcaggtgaaaatggggagagaatg
aaagaaaagtacggtgtgttttgtagtggccacaatgaagctgttagtcattacaagttg
ctgcttcagcaaaacaagaaatttcaaaacttgatcaagaaaattggcaacttctccatc
gtgcggcggcttggcgtgcaggagtgcattctcctggttacacaacgcataaccaaatac
ccagtgctggtggagcgcatcatccagaacacggaagctggcactgaggactatgaagac
ctgacccaggccttgaacctcatcaaagatatcatctcacaagtggacgccaaggtcagt
gagtgtgagaagggccagcgcctcagggagatcgcagggaagatggacctgaagtcttcc
agcaaactcaagaacgggctcaccttccgcaaggaagacatgcttcagcggcagctccac
ctggagggcatgctatgctggaagaccacatcagggcgcttgaaagatatcctggctatc
ctgctgaccgacgtacttttgctgctacaagaaaaagatcagaaatacgtctttgcttct
gtggactcaaagccacccgtcatctcgttacaaaagctcatcgtgagggaagtggccaac
gaggagaaagcgatgtttctgatcagcgcctccttgcaagggccggagatgtatgaaatc
tacacgagctccaaagaggacaggaacgcctggatggcccacatccaaagggctgtggag
agctgccctgacgaggaggaggggcccttcagcctgcccgaagaggaaaggaaggtggtc
gaggcccgcgccacgagactccgggactttcaagagcggttgagcatgaaagaccagctg
atcgcacagagcctcctagagaaacagcagatctacctggagatggccgagatgggcggc
ctcgaagacctgccccagccccgaggcctattccgtggaggggacccatccgagaccctg
cagggggagctaattctcaagtcggccatgagcgagatcgagggcatccagagcctgatc
tgcaggcggctgggcagcgccaacggccaggcggaagacggaggcagctccacaggcccg
cccaggagggctgagaccttcgcgggctacgactgcacaaacagccccaccaagaatggc
agtttcaagaagaaagtcagcagcactgaccccaggccccgagactggcgaggcccccca
aacagcccggacttgaagctcagtgacagtgacattcctgggagctctgaggaatcgccg
caggtggtggaggcgccaggcacggaatccgatccccgtctgcccaccgtcctggagtcg
gagcttgtccagcggatccagacactgtcccagctgctcctgaaccttcaggcggtaatc
gcccaccaggacagctatgtggagacgcagcgggctgccatccaggagcgggagaagcag
ttccggctgcagtcgacgcgtgggaacctgctgctggagcaggagcggcaacgcaacttc
gagaagcagcgggaggagcgcgcggccctggagaagctgcagagccagctgcggcacgag
cagcagcgctgggagcgcgagcgccagtggcagcaccaggagctggagcgtgcgggcgcg
cggctgcaggagcgcgagggcgaggcgcggcagctacgcgagcggctggagcaggagcgg
gccgagctggagcgccagcgccaggcctaccagcacgacctggagcggctgcgcgaggcc
cagcgtgccgtggagcgcgagcgggagcgcctggagctgctgcgccgcctcaagaagcag
aacaccgcgccaggcgcgctgccgcccgacacactggccgaggcccagcccccaagccac
cctcccagcttcaacggggaagggctggagggccctcgggtgagcatgctgccatccggc
gtggggccagagtacgcagagcgccccgaggtggctcgccgggacagcgcccccaccgag
agccggctggccaagagcgatgtgcccatccagctgctcagcgccaccaaccagttccag
aggcaggcggccgtgcagcagcagatccccaccaagctggcggcctccaccaagggtggc
aaggacaagggcggcaagagcaggggctctcagcgctgggagagctcagcgtccttcgac
ctgaagcagcagctgctgctcaacaagctcatggggaaagatgagagcacctcacggaac
cgccgctcgctgagccctatcctgcccggcagacacagtcctgcgcccccaccagaccct
ggcttccccgccccgagcccaccgccagctgacagcccctccgagggcttctctctcaag
gccgggggcacagccctcctgcccggccccccagctccctcgccactgccggccacacca
ctcagcgccaaggaggacgccagcaaagaagacgtcatcttcttcttaatta
Protein Sequence
>ARHGEF18
MTVSQKGGPQPTPSPAGPGTQLGPITGEMDEADSAFLKFKQTADDSLSLTSPNTESIFVE
DPYTASLRSEIESDGHEFEAESWSLAVDAAYAKKQKREVVKRQDVLYELMQTEVHHVRTL
KIMLKVYSRALQEELQFSSKAIGRLFPCADDLLETHSHFLARLKERRQESLEEGSDRNYV
IQKIGDLLVQQFSGENGERMKEKYGVFCSGHNEAVSHYKLLLQQNKKFQNLIKKIGNFSI
VRRLGVQECILLVTQRITKYPVLVERIIQNTEAGTEDYEDLTQALNLIKDIISQVDAKVS
ECEKGQRLREIAGKMDLKSSSKLKNGLTFRKEDMLQRQLHLEGMLCWKTTSGRLKDILAI
LLTDVLLLLQEKDQKYVFASVDSKPPVISLQKLIVREVANEEKAMFLISASLQGPEMYEI
YTSSKEDRNAWMAHIQRAVESCPDEEEGPFSLPEEERKVVEARATRLRDFQERLSMKDQL
IAQSLLEKQQIYLEMAEMGGLEDLPQPRGLFRGGDPSETLQGELILKSAMSEIEGIQSLI
CRRLGSANGQAEDGGSSTGPPRRAETFAGYDCTNSPTKNGSFKKKVSSTDPRPRDWRGPP
NSPDLKLSDSDIPGSSEESPQVVEAPGTESDPRLPTVLESELVQRIQTLSQLLLNLQAVI
AHQDSYVETQRAAIQEREKQFRLQSTRGNLLLEQERQRNFEKQREERAALEKLQSQLRHE
QQRWERERQWQHQELERAGARLQEREGEARQLRERLEQERAELERQRQAYQHDLERLREA
QRAVERERERLELLRRLKKQNTAPGALPPDTLAEAQPPSHPPSFNGEGLEGPRVSMLPSG
VGPEYAERPEVARRDSAPTESRLAKSDVPIQLLSATNQFQRQAAVQQQIPTKLAASTKGG
KDKGGKSRGSQRWESSASFDLKQQLLLNKLMGKDESTSRNRRSLSPILPGRHSPAPPPDP
GFPAPSPPPADSPSEGFSLKAGGTALLPGPPAPSPLPATPLSAKEDASKEDVIFFLI